This release includes significant updates and new integrations, including support for Google BigQuery and Databricks, new features for Snowflake, Microsoft Fabric and SQL Server. We’ve also added support for upgrading Flow packages, significant performance improvements to Calculation Flows, additional Core library actions and a few important bug fixes.
PowerOffice Go
Profitbase Flow now has a built-in connector for the PowerOffice Go REST API. The connector handles authentication, paging, faults and throttling (API quotas), simplifying data integrations with PowerOffice Go.
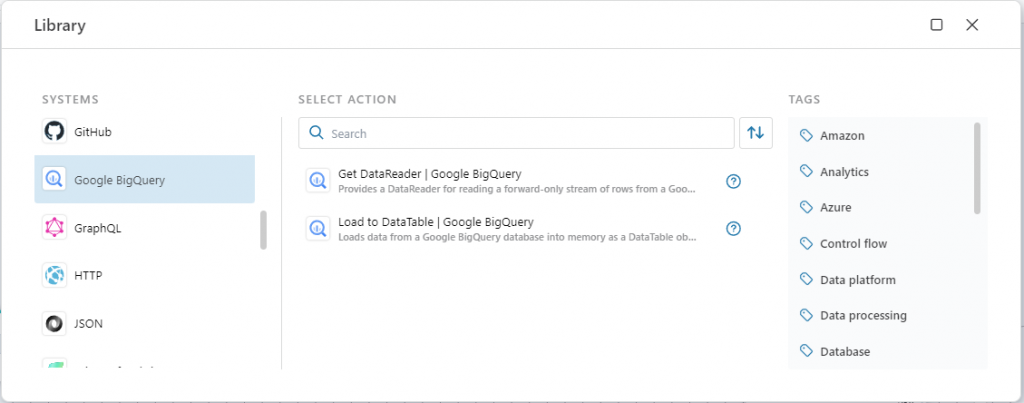
Google BigQuery
This release introduces support for integration with Google BigQuery for reading data. We’ve initially added support for just reading data, but we plan to add actions for writing / importing data soon :
- Get DataReader – reads data as a stream of rows from Google BigQuery. You will typically use this action for moving data from Google BigQuery to a different system, such as a database or file,
- Load to DataTable – loads data from Google BigQuery into memory. You will typically use this action for smaller datasets to perform in-memory operations on the whole dataset before sending the result to a service or database.
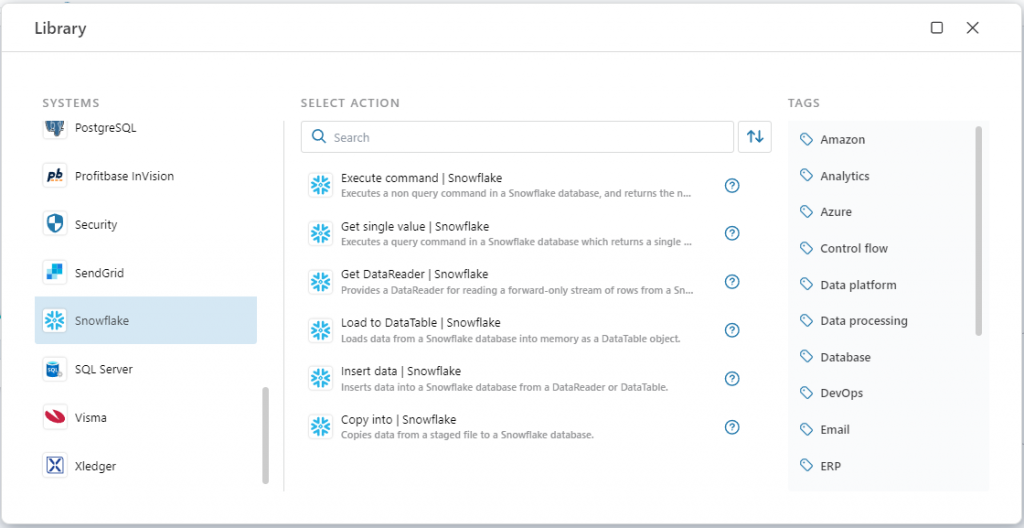
Snowflake
In this release, we’ve extended our support for Snowflake with multiple actions for reading and writing data, including:
- Load to DataTable – loads data from Snowflake into memory. You will typically use this action for smaller datasets to perform in-memory operations on the whole dataset before sending the result to a service or database.
- Insert Data – inserts data from a DataTable or IDataReader into a Snowflake table.
- COPY INTO – used for loading large volumes of data into Snowflake from files such as Parquet, CSV or JSON.
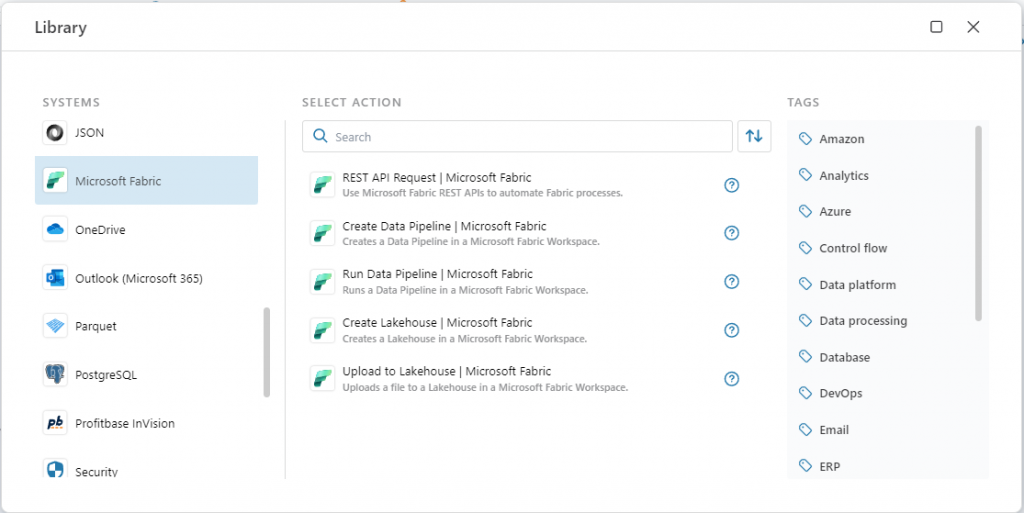
Microsoft Fabric
This release adds support for the following new features:
- Create Data Pipeline – enables creating Data Pipelines in Microsoft Fabric. This action supports creating Data Pipelines with a configuration, so you can deploy pre-defined Data Pipelines to Fabric.
- Run Data Pipeline – enables running Data Pipelines in Microsoft Fabric from Flow. We support parameterization.
- Create Lakehouse – enables creating a Lakehouse from Flow.
- Upload to Lakehouse – enables uploading files directly to a Fabric Lakehouse, so you don’t need intermediary storages or Data Pipelines for getting data into a Lakehouse.
- Microsoft Fabric Connections can now use either Service Principal or User authorization. Not all Fabric REST APIs support both User and Service Principal permissions, so you need to refer to the Fabric docs to understand which connection type to create based on your scenario.
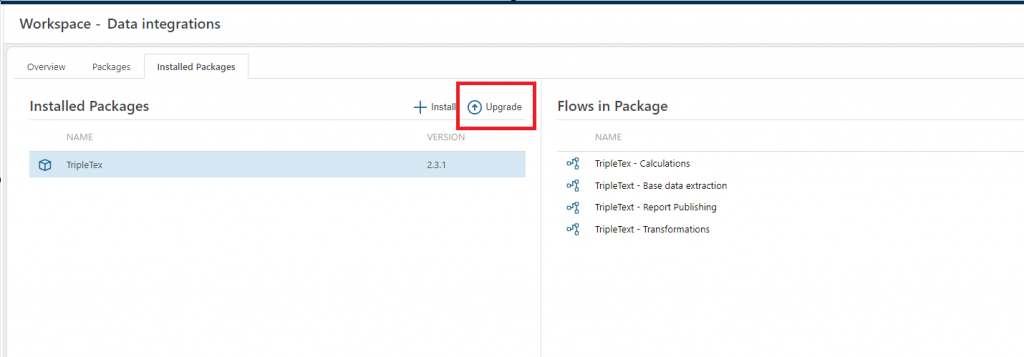
Package Manager
Flow packages can now be upgraded from the Flow package manager. This enables customers to easily upgrade packages to new versions.
JSON
You can now both read and create JSON files using Flow, making it easy to for example pipe results from HTTP APIs directly to Azure Blob Storage, Amazon S3 or OneLake.
SQL Server
The Transaction scope action now supports the following Isolation level
- Read committed
- Read uncommitted
- Repeatable read
- Serializable
- Snapshot
Improved Calculation Flow performance
We’ve significantly increased the performance of InVision Calculation Flows. The average execution time of InVision Calculation Flows has decreased from 10-15 seconds, to ~1 second or lower.
Core library
The Core library has been extended with the following functionality
- Action to Unescape unicode characters from a string. A typical use case for this action is when processing raw JSON returned from HTTP APIs, and the returned JSON string contains unicode escaped characters. This action converts “Europa s\u00f8r” to “Europa Sør”.
- Action to Remove InVision object from cache. Use this action if you modify InVision objects such as Dimensions, Lookup, Auto transaction or Distribution key tables programmatically through SQL Scripts or Stored Procedures instead of through InVision APIs.
Bug fixes
- Fixed an issue where the JSON Editor parsed JSON documents containing multiple variable references incorrectly.
- Fixed an issue where the JSON Editor removed the property names of JavaScript array properties
- Fixed an issue where the JSON Editor added quotes around numeric literals
- Fixed an issue in the Flow scheduler which caused scheduled Flows to not start