We are excited to release the first version of Flow with support for AI workloads powered by Azure and Open AI! In this first AI-centered release, we’ve focused on adding support for accessing information in business documents through semantic search, AI chat and AI agents. You can now use Flow to build document stores for RAG (and semantic search), AI chat clients, and automate tasks using AI agents.
Adobe PDF Services
You can now use Adobe PDF Services in Flow to easily convert PDF files to Word (.docx), Excel (.xlsx), PowerPoint (.pptx) and RTF (.rtf) files.
Information stored in PDF files is largely inaccessible to other tools and systems until it is extracted into a more standard, or machine readable, format. For example, if you want to use content from PDFs in LLM-based workloads—such as generating summaries, making the content searchable in a database, or reasoning over it—you need to convert the information into a text-based format like Markdown. By combining an Adobe PDF Services converter action with a Markdown converter action, you can make PDF files accessible to LLMs and other information retrieval systems.
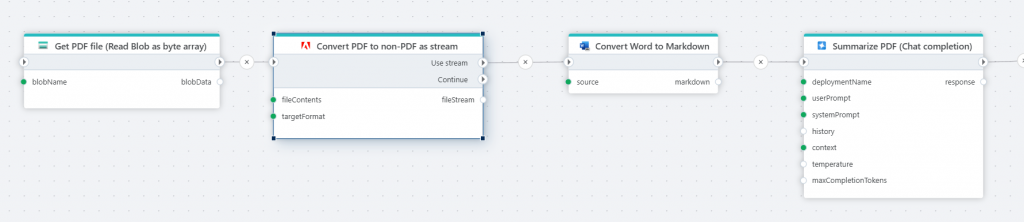
AI Tools Agent
The Tools AI Agent enables creating AI-powered automations where AI Agents, given a set of tools, can operate autonomously to complete tasks.
For example, an AI agent can be tasked with collecting information from various internal business systems, compose a report, and post the report to a Teams channel. For this purpose, the agent will need a “brain” to reason about what to do, and a set of tools to collect data from the business systems and post the report to Teams. The “brain”, which typically is an LLM, will analyze the task, decide which tools to use, and then call the tools to achieve the desired outcome.
Read more here
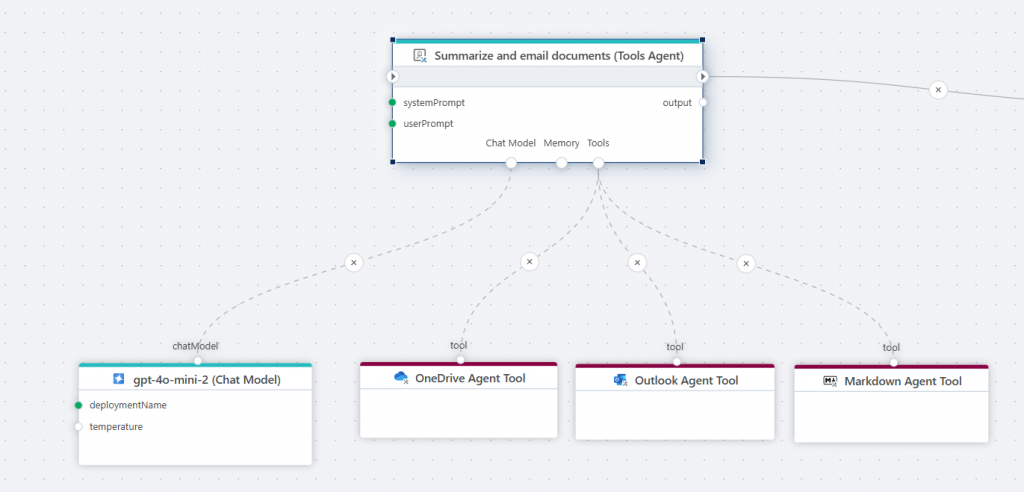
AI Agent Tools
Tools enables building AI-powered automations using AI Agents that, given a set of tools, can operate autonomously to complete tasks. The May 2025 update of Flow includes the following AI Agent Tools to use for building AI powered automations.
- Azure Storage Blob Agent Tool
This tools enables the Tools AI Agent to access Azure Blob Storage to perform actions, such as reading and writing files.
- OneDrive Agent Tool
This tool enables the Tools AI Agent to access OneDrive on behalf of a user to list, read, upload and delete files.
Read more here
- Outlook Agent Tool
This tool enables the Tools AI Agent to access Outlook on behalf of a user to send emails.
Read more here
- Markdown Agent Tool
This tool enables an AI Agent to convert Word, PowerPoint, PDF, CSV and Excel files to Markdown files. An AI Agent will typically need this tool if given tasks that requires reading and understanding the contents of files, for example summarizing documents. Files such as Word and PowerPoint does not store data in a (text) format understandable to LLMs, so converting to a text format like Markdown is required before the LLM can reason about the contents.
AI Chat – Azure OpenAI
Chat completion
Given a prompt (user input), the (Azure OpenAI) Chat completion action returns a response from an Azure OpenAI chat model (LLM). A typical use case is to create chat clients (like ChatGPT) or reason about contents of documents.

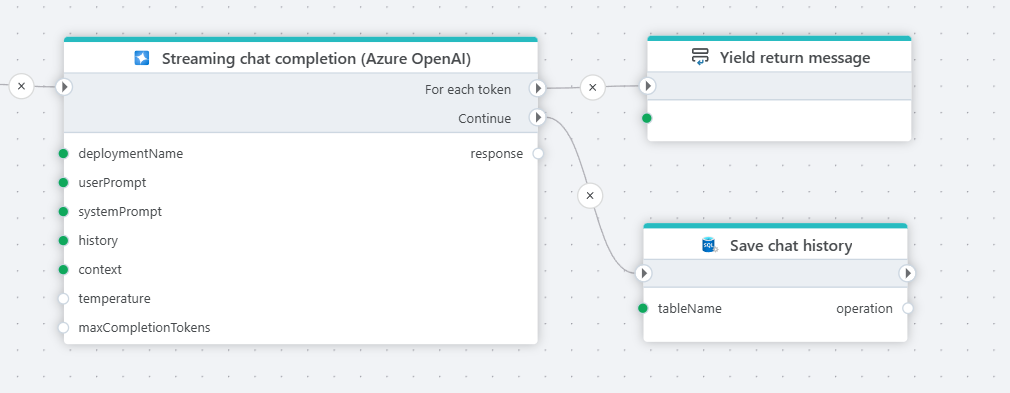
Streaming chat completion
This action does the same as the Chat completion above, except that it streams back the response from the LLM as soon as it becomes available instead of waiting for the entire response to complete. This makes it ideal for implementing chat client backends, but less suited for automation workflows with no user interaction.
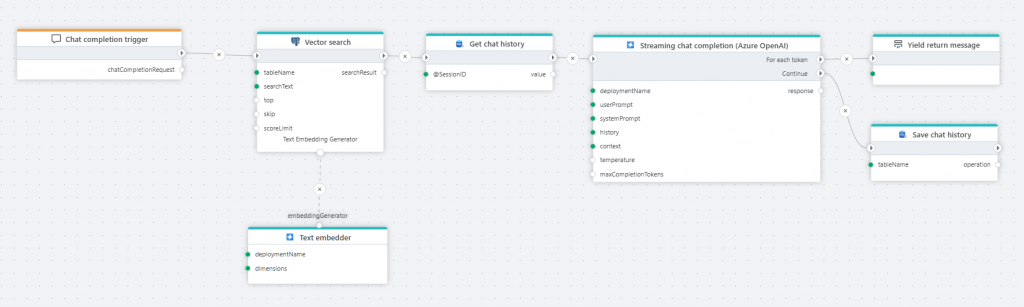
Generate embedding
This action enables generating an embedding vector from a string (text) so it can be used to do a vector search or to create a record in a vector store (for example SQL Server or PostgreSQL).
Read more here.
Chat model
When a node like the Tools AI Agent is given a task, it uses a Chat model to reason about what to do, and how to it. The chat model is basically the brain of an AI Agent or any other LLM-powered process.
Read more here.
Text embedder
The Text embedder is a tool used by actions such as the PostgreSQL Vector search action to generate embedding vectors on demand. The action chooses when and if to use the tool.
The difference between the Text embedder tool and the Generate embedding action, is that the Text embedder tool is used by other actions if they choose to, while the Generate embedding action runs explicitly.
AI Chat – OpenAI
Chat completion
Given a prompt (user input), the (OpenAI) Chat completion action returns a response from an OpenAI chat model (LLM). A typical use case is to create chat clients (like ChatGPT) or reason about contents of documents.
Read more here.
Streaming chat completion
This action does the same as the Chat completion above, except that it streams back the response from the LLM as soon as it becomes available instead of waiting for the entire response to complete. This makes it ideal for implementing chat client backends, but less suited for automation workflows with no user interaction.
Generate embedding
This action enables generating an embedding vector from a string (text) so it can be used to do a vector search or to create a record in a vector store (for example SQL Server or PostgreSQL).
Chat model
When a node like the Tools AI Agent is given a task, it uses a Chat model to reason about what to do, and how to it. The chat model is basically the brain of an AI Agent or any other LLM-powered process.
Read more here.
Text embedder
The Text embedder is a tool used by actions such as the PostgreSQL Vector search action to generate embedding vectors on demand. The action chooses when and if to use the tool.
The difference between the Text embedder tool and the Generate embedding action, is that the Text embedder tool is used by other actions if they choose to, while the Generate embedding action runs explicitly.
AI Chat – Common
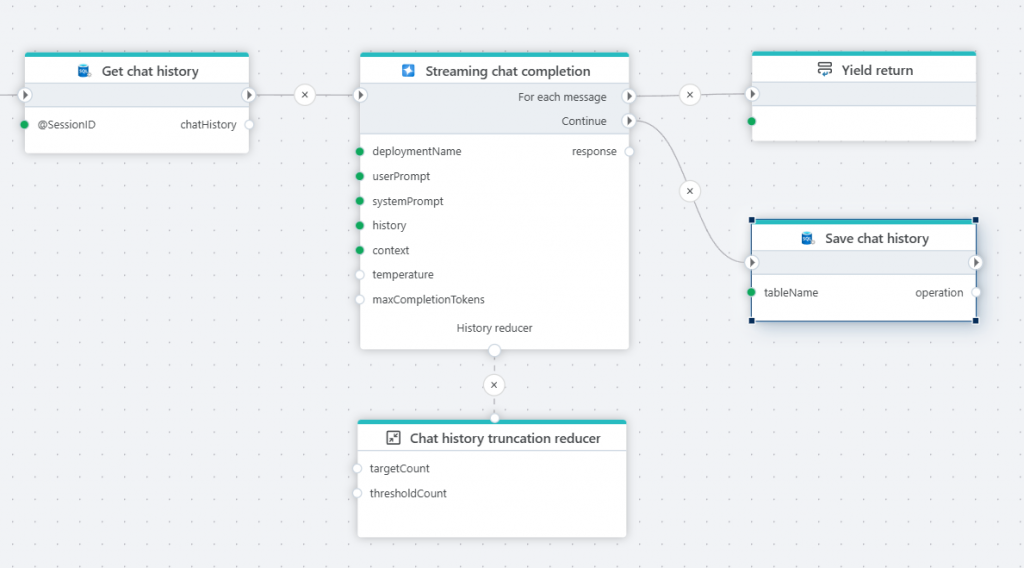
Chat history truncation reducer
The Chat history truncation reducer is used to limit the amount of data processed by an LLM by removing items from the chat history before it is sent as part of the prompt. Reducing the input to an LLM may positively affect the accuracy of the response, and reduce cost because fewer tokens are used.
PostgreSQL
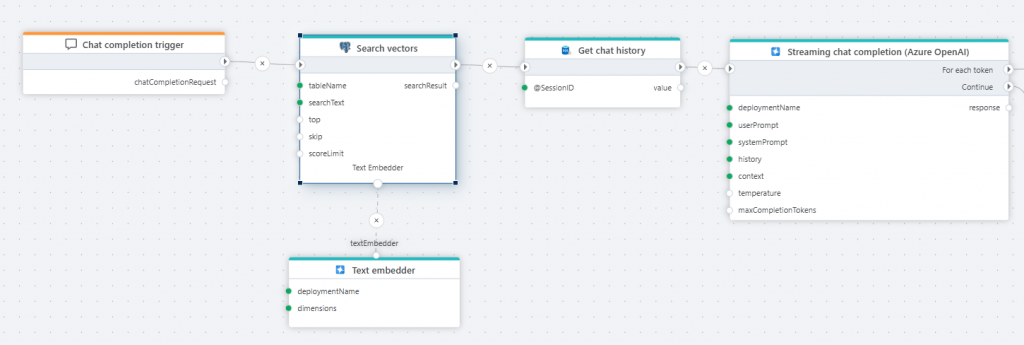
Search vectors
This action performs a vector search against a PostgreSQL table and returns the matching records. It is typically used when you want to find similar items based on meaning or characteristics, rather than exact matches. Common use cases includes
- Semantic search: Retrieving documents, web pages, or support articles that are semantically similar to a user’s query, even if they don’t share the same keywords.
- Recommendation systems: Suggesting similar products, movies, songs, etc., by comparing vector representations of items and user preferences.
A concrete example for using the vector search action is when building RAG-based pipelines, where you are using an LLM to answer questions or reason about text. For this, you will do a semantic search for the question asked by the user, and then feed the result of the search + the user question to the LLM.
Markdown
Markdown is a lightweight plain-text formatting language used to create structured documents using simple syntax (e.g., # for headings, * for bullets, backticks for code). It is easy to read, write, parse and generate, making it ideal for LLMs and AI-enabled workloads.
The following actions are supported:
Convert URL to Markdown
Converts the HTML content of a web page into Markdown format.
Read more here.
Convert HTML to Markdown
Converts HTML to Markdown using the MarkItDown library from Microsoft.
Read more here.
Convert a PDF file to Markdown
Converts a PDF file to Markdown using the MarkItDown library from Microsoft.
Read more here.
Convert an Excel file to Markdown
Converts an Excel file to Markdown using the MarkItDown library from Microsoft.
Read more here.
Convert a Word file to Markdown
Converts a Word file to Markdown using the MarkItDown library from Microsoft.
Read more here.
Convert a PowerPoint file to Markdown
Convert a PowerPoint file to Markdown using the MarkItDown library from Microsoft.
Read more here.
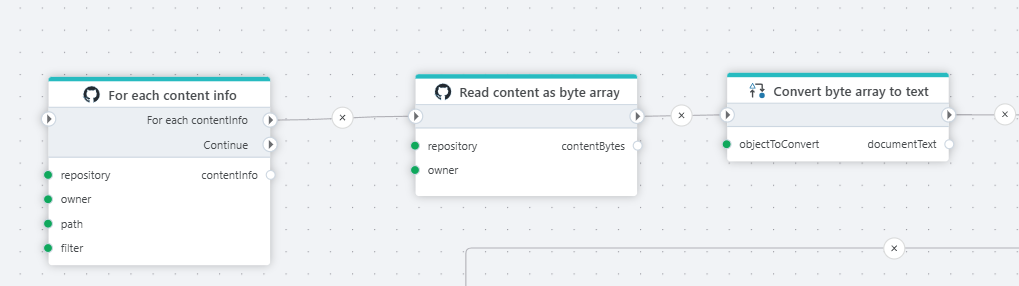
GitHub
We have added support for reading reading files and file information from GitHub repositories. This enables using Flow for workloads involving pulling resources from GitHub, for example deploying Spark Jobs or Notebooks to Microsoft Fabric as part of deploying data integration solutions.
For each content info
This action iterates over file and folder information is a GitHub repository. Note that it does not download any files. You will typically use this action to list items, and then conditionally download the ones you are after.
Read more here.
Read content as byte array
This action reads a file from GitHub as byte array (binary format, can be used multiple times).
Read more here.
Read contents as stream
This action reads a file from GitHub as stream (read once, forward only, best performance).
The difference between reading a file as stream or byte array, is that a stream can only be read once. If you need to perform multiple operations on the same file, use the byte array option.
Read more here.
HTML
We’ve added basic support for web scraping, which enables automating retrieval of information from web sites for analysis or storing to files or databases.

For each HTML element
This action supports iterating over HTML elements in an HTML document or HTML fragment. You can use this action when doing web scraping to get contents of a web site, and you need to extract data from only specific sections of the web pages.
Read more here.
Replace relative with absolute URLs
This action replaces relative URLs in an HTML document or element with absolute URLs.
A typical use case for this action is storing information from a website (such as an internal knowledge base) in a vector database used for RAG by an AI chat. Links to topics are often stored as URLs relative to the original site. However, when an LLM replies with information from the RAG lookup, the response is no longer in the context of the original website, so relative links are broken.
Read more here.
HTTP
Get sitemap
This action retrieves the sitemap from a given URL and returns a structured list of entries, including metadata for each page. It is typically used as a starting point for scraping pages on the website.
Read more here.
Vector data
Split text
The Split text actin breaks large blocks of text into smaller, manageable chunks. This is especially useful in natural language processing tasks, where models have input size limits or where splitting improves performance. Text splitters typically aim to preserve semantic meaning by splitting at logical boundaries like sentences or paragraphs.
When using Flow to populate a vector database with text from sources like documents or websites, use the Text Splitter to break large blocks of text into smaller chunks before generating embeddings and storing them in the database.

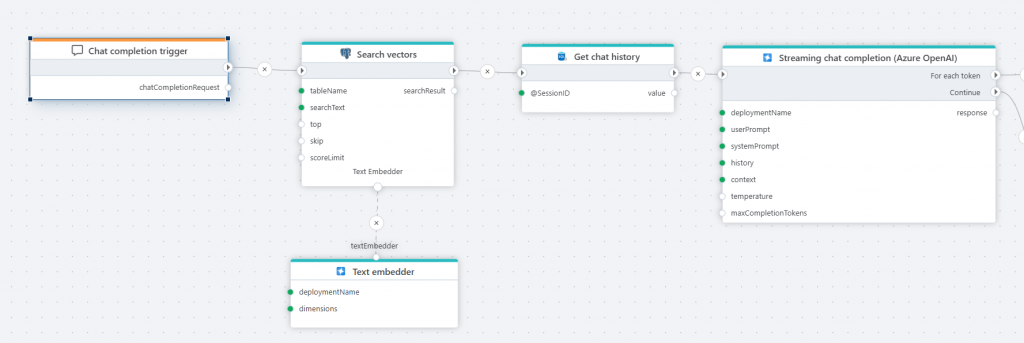
Chat completion trigger
The Chat completion trigger defines the entry point for a Flow that executes an AI chat completion request.
You’ll typically use this trigger when you want to implement a Flow that serves as the backend for an interactive chat, allowing users to have a conversation with an AI by asking questions and follow-up questions. The trigger also provides a context property, allowing arbitrary data to be passed to the Flow to use for filtering or other types of business logic, supporting features such as RAG to help the LLM generate more relevant responses.
Read more here.
JSON
JsonDataReader – handle arrays
The JsonDataReader API, including the Get JSON DataReader action, now reads array fields as raw strings instead of ignoring them. This feature enables working with JSON data that contains one-to-many relationships, such as transactions and transaction details (like orders and order lines).
Read more here.
InVision
Refresh Table artifacts
This action refreshes artifacts associated with InVision Tables.
You must use this action if you modify data in Tables using a SQL Script or other methods that directly manipulate the database table, instead of using InVision of Flow APIs.
You don’t have to use this action when updating InVision Tables using the built-in data import APIs or when users updates data through the UI.
Read more here
CSV
Support for parameterization of CSV export and import options (Advanced)
We now support parameterization of the CSV export and import options (such as row delimiter, quote character, thousand separator, date format string, etc), to enable apps such as Planner to create custom UIs for CSV data export and import jobs.
Core
Streaming
Profitbase Flow now supports streaming the result back to a client while executing. This enables clients to start processing data as soon as it becomes available, instead of having to wait until the Flow has completed the entire task. A typical use case of this feature is to build AI chat clients, where the response from the LLM is streamed back in chunks as it becomes available.
Read more here
Yield break
The yield break action signals the end of an iteration in an iterator. When a client receives this signal, it knows that no more items are returned.
Read more here
Yield return
Yield return provides the next value of an iteration in an iterator – in other words, it returns the current chunk of a response. When there is no more data to yield back to the client, Yield break signals the end of the response.
Read more here.
Run Flow – Parameterizable target Flow
When using the Run Flow action, you can now parameterize which Flow to run, enabling creating more general purpose and composable Flows.
That’s it for now
Happy automation!