The June 2025 update expands the toolbox for building AI-powered solutions with support for Model Context Protocol, the ability to use SQL Server and Azure SQL Database as vector stores, and additional Adobe PDF Services APIs for ingesting, extracting, and processing information from PDF files.
Support for Model Context Protocol (MCP) enables finances and operations teams to build AI agents and agentic workflow automations with Flow. Combined with the extensive library of ERP, database and service connectors, finance and operation teams can now create AI-powered agents that automate dataflows between systems, enforces business rules, analyzes information, and eliminates manual work.
Enough talk – let’s get into the details below 🙂
Model Context Protocol (MCP) – Build AI agents with Flow
TL;DR You can now build AI agents with Flow. You can also integrate external AI agents into Flow, and let external AI agents integrate with Flow.
Model Context Protocol (MCP) enables building AI agents. It is an open standard that defines how AI models, particularly large language models (LLMs), interact with external tools, systems, and data sources. MCP enables LLMs to take concrete actions, instead of just generating text responses. With MCP, LLMs are no longer just chatbots – they can drive business processes and perform actual tasks. For example, you can make AI models interact with your ERP system through MCP to perform various tasks such as fetching customer data, update inventory records, and automate invoice processing.
With Flow, you can now build MCP tools and AI agents, and use external MCP tools (servers) in the mix. The MCP tools you create in Flow can also be used by external AI agents, such as Microsoft 365 Copilot agents.
MCP client tool
This tool enables building AI agents in Flow by providing a way for AI models to interact with external systems via MCP servers.
The image below shows an AI agent that runs periodically, uses tools from two MCP servers to check the production line status, and notify users if actions need to be taken. With the MCP client tool, you can now use Flow to build AI agents that uses both 3rd party AI tools, and the tools developed by you.
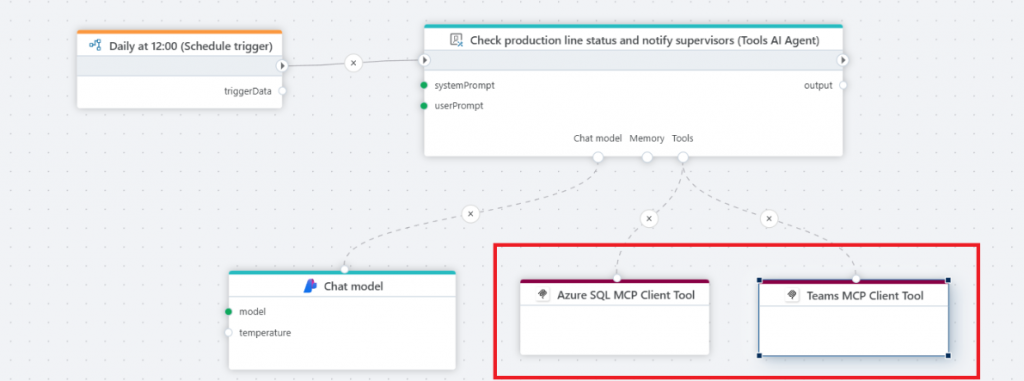
MCP tool trigger
The MPC tool trigger exposes a Flow as an AI tool compatible with MCP (Model Context Protocol), making it accessible to LLMs. This means that you can use the entire Flow toolbox to build agentic AI automations. The image below shows an AI tool build with Flow that can be used by an Order management (AI) agent to place an order and send an order confirmation email.
Read more here.

Adobe
Because PDFs are heavily used as an information exchange format between businesses, we’ve added several more actions to ingest, extract and process information from PDF files so it can be easily stored and retrieved by internal business systems, such as ERP, databases or custom apps.
Extract content from PDF document as byte array, stream, JSON or document (object model) tree
When receiving data via PDF, such as orders or invoices (often via email), you usually need to extract the information from the documents, classify and store the information into your business systems – and kick off a workflow based on the received information. The new PDF extraction actions converts the information from PDF files into structured JSON (plain text) that can be used for further processing. This enables building automated workflows for processing contents in PDF files.
The image below shows an automation Flow that processes invoice attachments from incoming email messages, extracts key invoice details, and registers the information in Dynamics 365 Business Central.
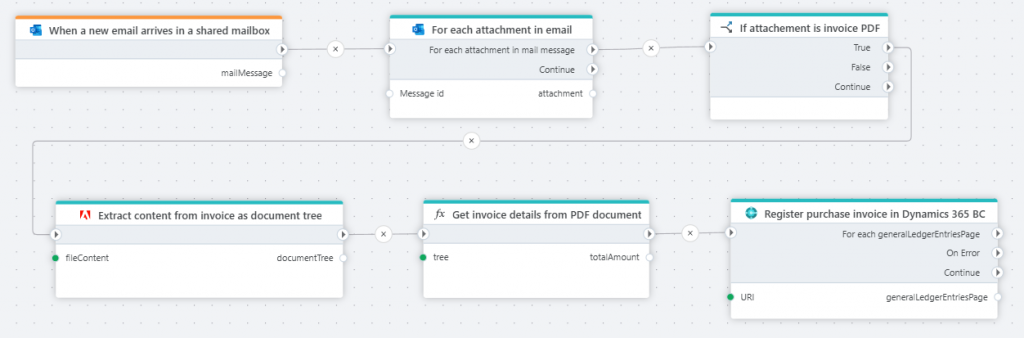
Read more about extraction to document tree here.
Read more about extraction to byte array here.
Read more about extraction to JSON here.
Convert non-PDF to PDF as byte array or stream
We now support converting non-PDF files (such as Word, image, PowerPoint, Excel, etc) to PDF files using Adobe PDF Services. While information is often maintained in formats like Word, Excel and PowerPoint within the company, it’s common to convert it to a “read-only” standard format when sharing with external parties such as customers, partners, investors, or board members. The new PDF convert actions enable you to automate workflows that involve compiling data from internal documents into PDF files.
Read more here.
PostgreSQL
Save vectors
The Save vectors actions makes it very easy to use PostgreSQL to build a vector store that you can use for semantic / similarity search in AI systems. Given an input as text (such as a document), it will automatically vectorize and store the information by splitting the document into chunks and generate embeddings for each chunk. If you re-run the action, it will update the representation of the document in the vector store, so that the vector store contains up-to-date and accurate information.
Search vectors – support for prompt templates and including metadata to LLMs
The Vector search action in PostgreSQL now support including metadata in the search result so it can be passed to LLMs in the prompt. A typical use case for this is when the LLM needs to provide source references for its response, for example which web page or document contains the information that was used to generate the response.
We also added support for user-defined prompt templates, allowing Flow developers to customize how prompts are presented to LLMs. This capability was added because different LLMs may respond differently depending on how input is structured. You might also want to adjust prompts based on the type of information provided or how you want the LLM to interpret and use that information.
Read more here.
Insert or update row
The new Insert or update row action for PostgreSQL enables inserting or updating a row in PostgreSQL without writing code.
Read more here.
SQL Server / Azure SQL
Although vector support is still in preview, we’re staying ahead by enabling the use of SQL Server / Azure SQL as a vector database for AI workloads. With the Save Vectors and Search Vectors actions, using SQL Server or Azure SQL as a vector store for semantic search is now easy in Flow.
Save vectors
The Save vectors actions makes it very easy to use SQL Server to build a vector store that you can use for semantic / similarity search in AI systems. Given an input as text (such as a document), it will automatically store the input by splitting the document into chunks and generate embeddings for each chunk. If you re-run the action, it will update the representation of the document in the vector store, so that the vector store contains up-to-date and accurate information.
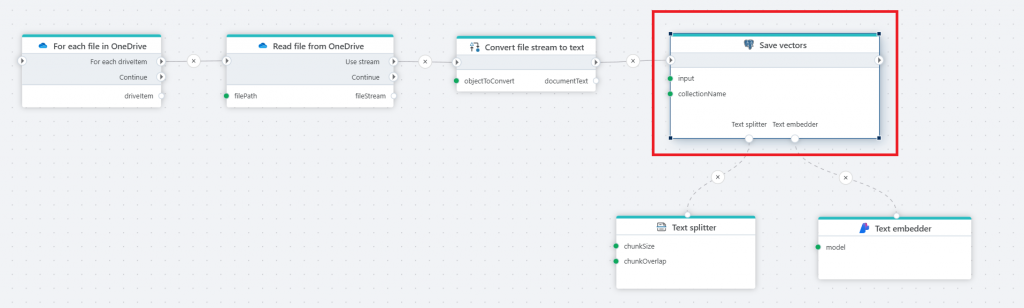
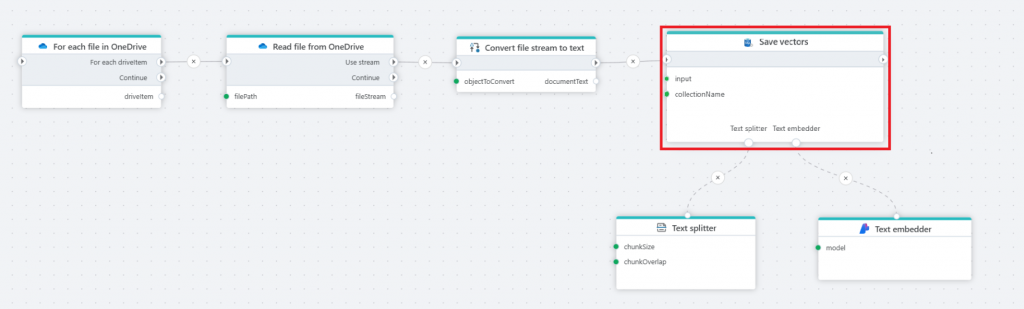
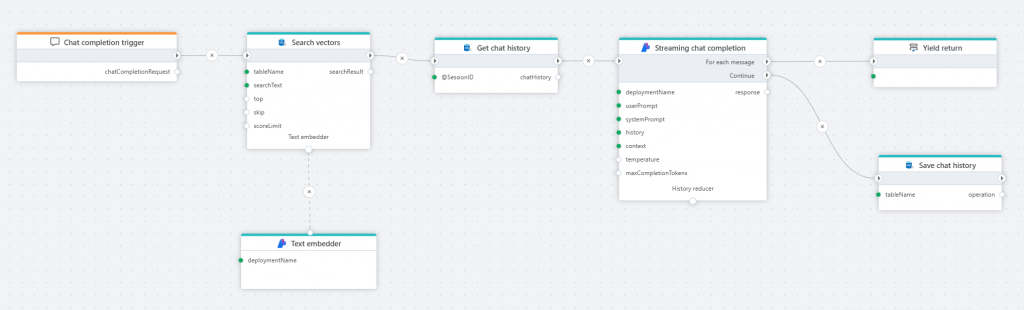
The Flow below illustrates how to create a knowledge database from files stored in SharePoint (OneDrive), and make the information available to AI agents or users via semantic search or AI chats. For example, let users use natural language chats to get information about product specs, marketing plans, HR handbooks and tender responses.
Search vectors
The Vector search action makes it very easy to use SQL Server as a vector database to do semantic search based on an input phrase, such as a question from a user or any other text that you want do do similarity search for. A very common use case in terms of AI, is to build RAG (retrieval augmented generation) systems, where you retrieve internal business information from the database using semantic / similarity search and then feed the results into an LLM for reasoning.
Core
Snowflake – include schema in table selector
The table selector now includes the schema so you don’t have to specify it manually if there is a naming conflict or you want to run cross-schema queries.
Log action
The new Log action is a utility function that you can use to do ad-hoc logging. This means that you no longer have to add a Function action simply to do logging.
Read more here.
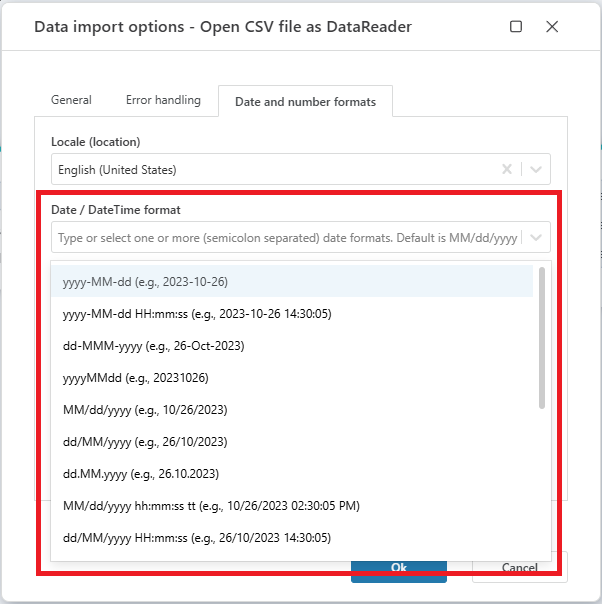
CSV – data format picker
This is a quality-of-life improvement for when working with the CSV import and dealing with date formats. Date formats are hard to remember, so we’ve now added a feature that lets you select from a list of the most commonly used date formats in CSV files. (You can still use custom formats as well).
JsonDataReader / Get JSON DataReader action
The JsonDataReader has received the following improvements:
- Schema mappings can now be added in random order. In previous versions, you had to define field mappings in the order they appeared in the source JSON document. You can now map fields in any order.
- Handles auto conversion to string for numeric properties that are schema mapped as strings. This issue was related to data type auto detection, where fields would get auto detected to be numeric early in the JSON document, but then switched to string later in the data set. You could typically get this issue when integrating with loosely typed ERP system APIs.
- When data conversion fails for a field, the field name is now included in the error message. This makes it easier to debug data flows that processes JSON documents.
Read more about Get JSON DataReader here.
Read more about the JsonDataReader API here.
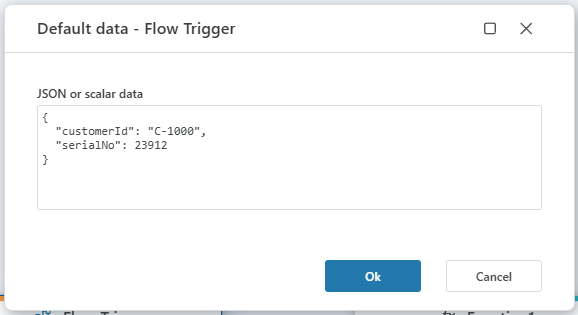
Flow trigger – support for default data
The Flow trigger now has support for defining a default data payload. Defining default data serves two main purposes:
- Simplify development by defining the test data to use during development.
- Define the default data to use if the caller Flow does not provide any data as input. Note that you should only do this if this behavior is intended. If null is a valid input, then remove the default data when development / testing is done.
The Default data definition must be a valid JSON value, meaning it can be a primitive type such as a string or number, or a complex JSON object.
Run Flow (nested execution) – streaming support
Nested execution now supports streaming data from the callee to the caller Flow. This means that the caller Flow can start processing data as it becomes available, instead of having to wait until the callee Flow has finished processing the entire request.
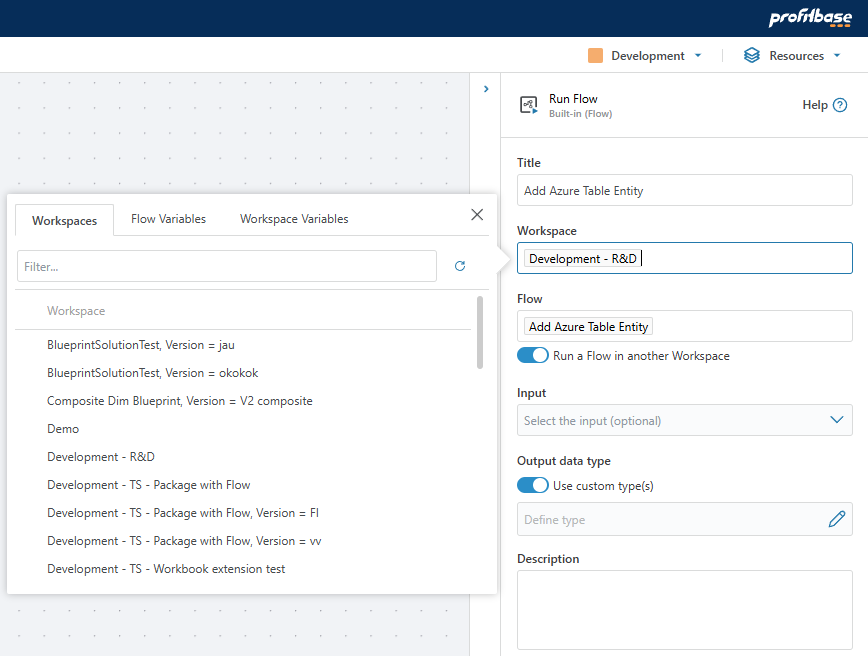
Run Flow (nested execution) – support for running Flows in other Workspaces
You can now run Flows in other Workspaces when using the Run Flow action. You can either specify the Workspace (and Flow) to run explicitly, or use parameterize both properties.
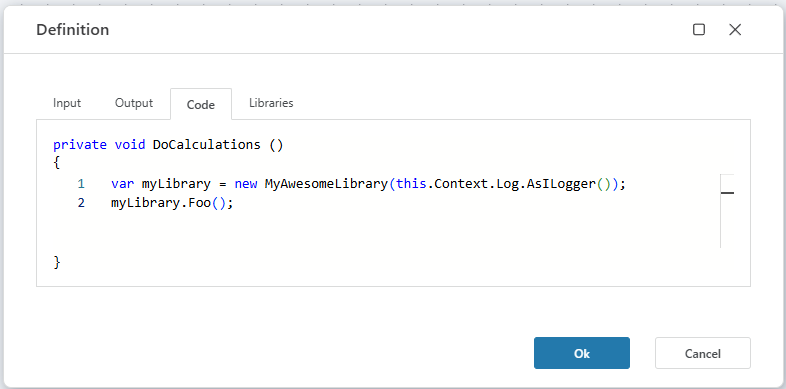
Log.AsILogger() – API for logging from extension libraries
When developing extension libraries to Flow (such as the Financials library), being able to write messages to the Flow log from within the library is often useful. These types of messages can range from debug messages used during development, to user-intended messages that describes what the library actually does. Providing insights into what mathematical or financial models does, and which parameters are used, makes the outcomes understandable and easier to interpret, evaluate, and trust.
That’s all for now!
May your summer be filled with joyful automation!